AAAI Preliminary Version: Link
Technical Supplement on ArXiv: Link
The goal of Approximate Query Processing (AQP) is to provide very fast but “accurate enough” results for costly aggregate queries thereby improving user experience in interactive exploration of large datasets. Recently proposed Machine-Learning based AQP techniques can provide very low latency as query execution only involves model inference as compared to traditional query processing on database clusters. However, with increase in the number of filtering predicates (WHERE clauses), the approximation error significantly increases for these methods. Analysts often use queries with a large number of predicates for insights discovery. Thus, maintaining low approximation error is important to prevent analysts from drawing misleading conclusions. In this paper, we propose ELECTRA, a predicate-aware AQP system that can answer analytics-style queries with a large number of predicates with much smaller approximation errors. ELECTRA uses a conditional generative model that learns the conditional distribution of the data and at runtime generates a small (~1000 rows) but representative sample, on which the query is executed to compute the approximate result. Our evaluations with four different baselines on three real-world datasets show that ELECTRA provides lower AQP error for large number of predicates compared to baselines.
Datasets
- Flights
- Dataset obtained from United States Department of Transporation - Bureau of Transportation Statistics’ website - Link.
- Table used was
On_Time_Reporting_Carrier_On_Time_Performance_1987_presentfor the year of 2019.
- Housing
- Dataset obtained from Kaggle - Link
- Beijing PM2.5
- Dataset obtained from UCI Machine Learning Repository - Link
Relative Error Plots
Figure 5
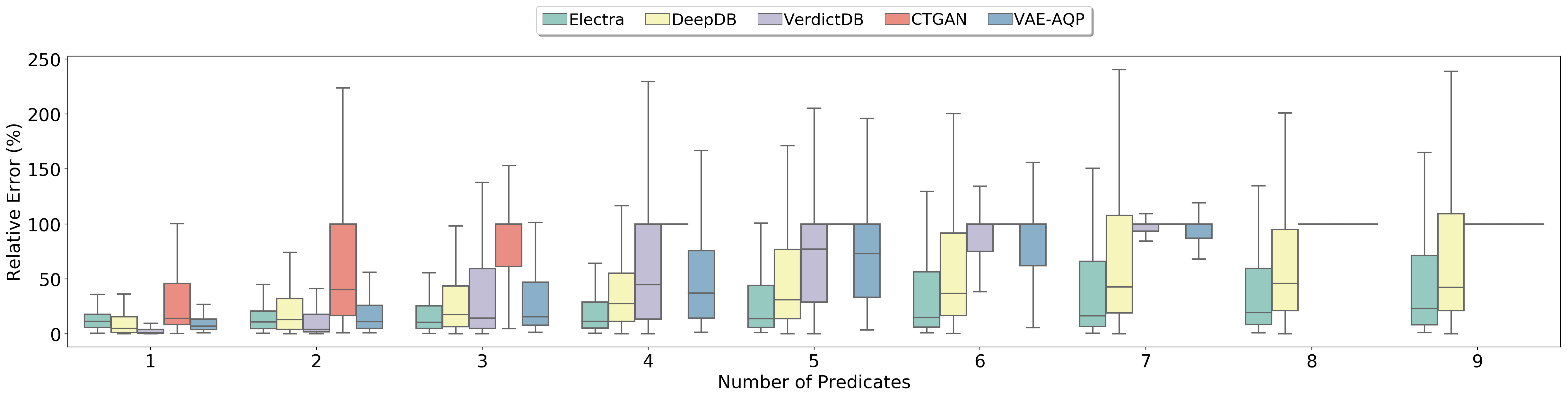 Flights Dataset
Flights Dataset
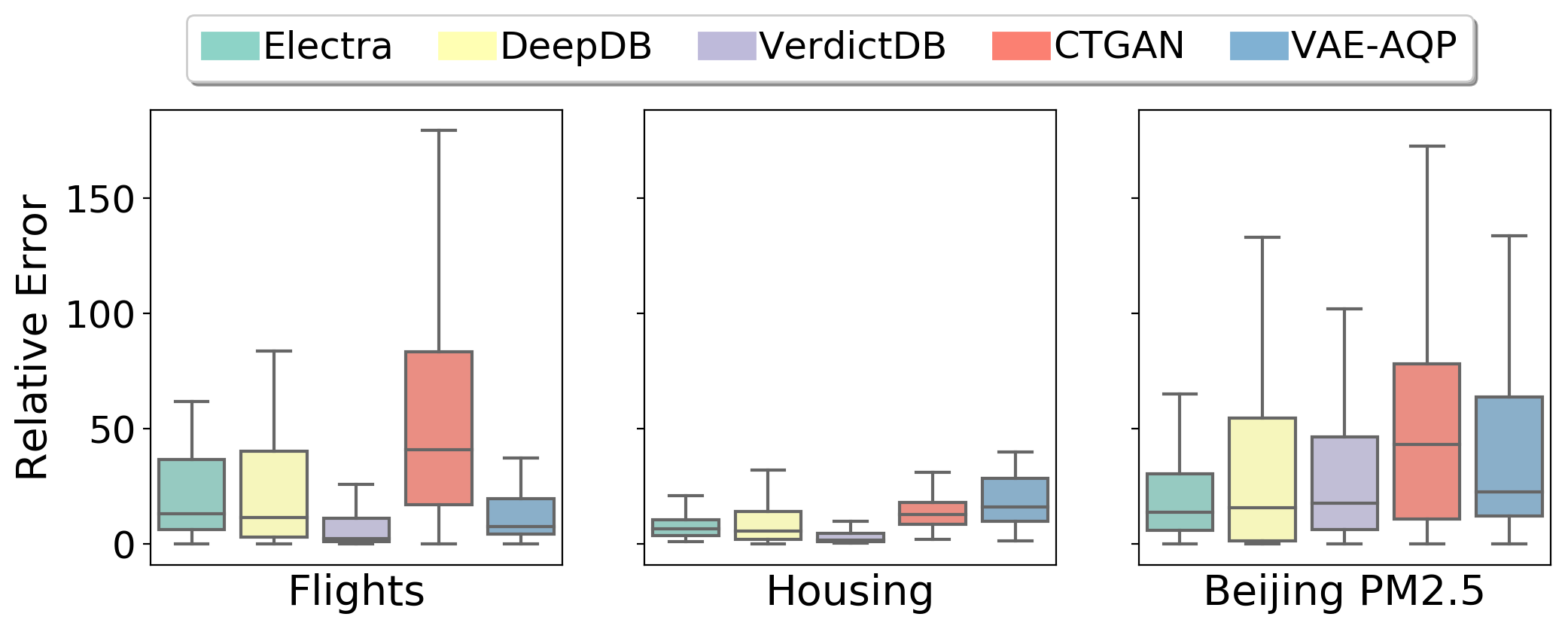
 Housing Dataset
Housing Dataset
 Beijing PM2.5 Dataset
Beijing PM2.5 Dataset
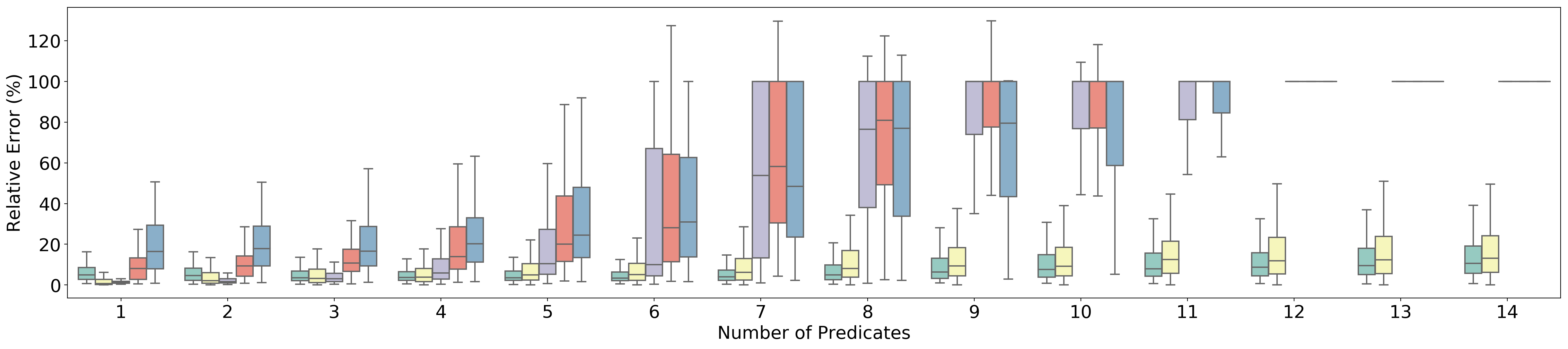
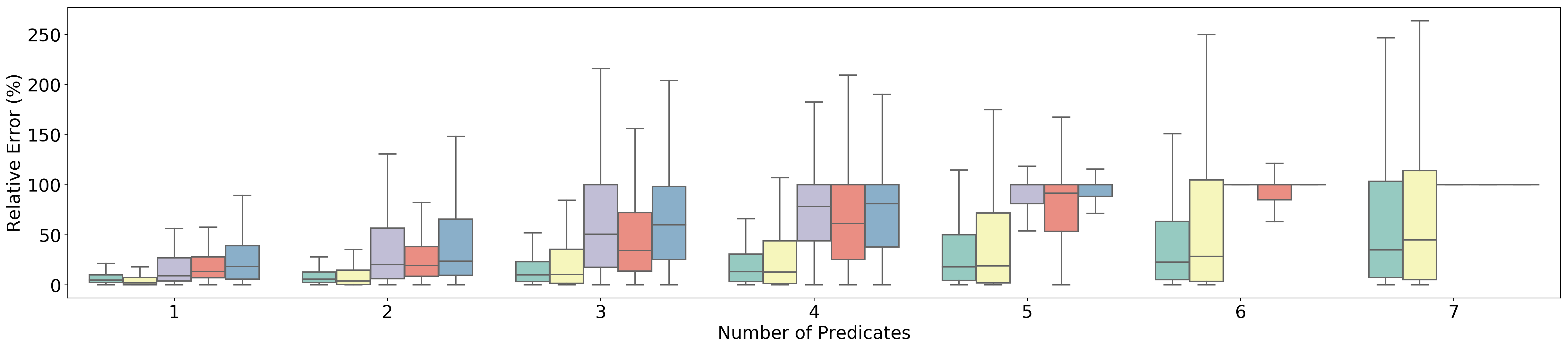
Figure 7
 AVG Queries
AVG Queries
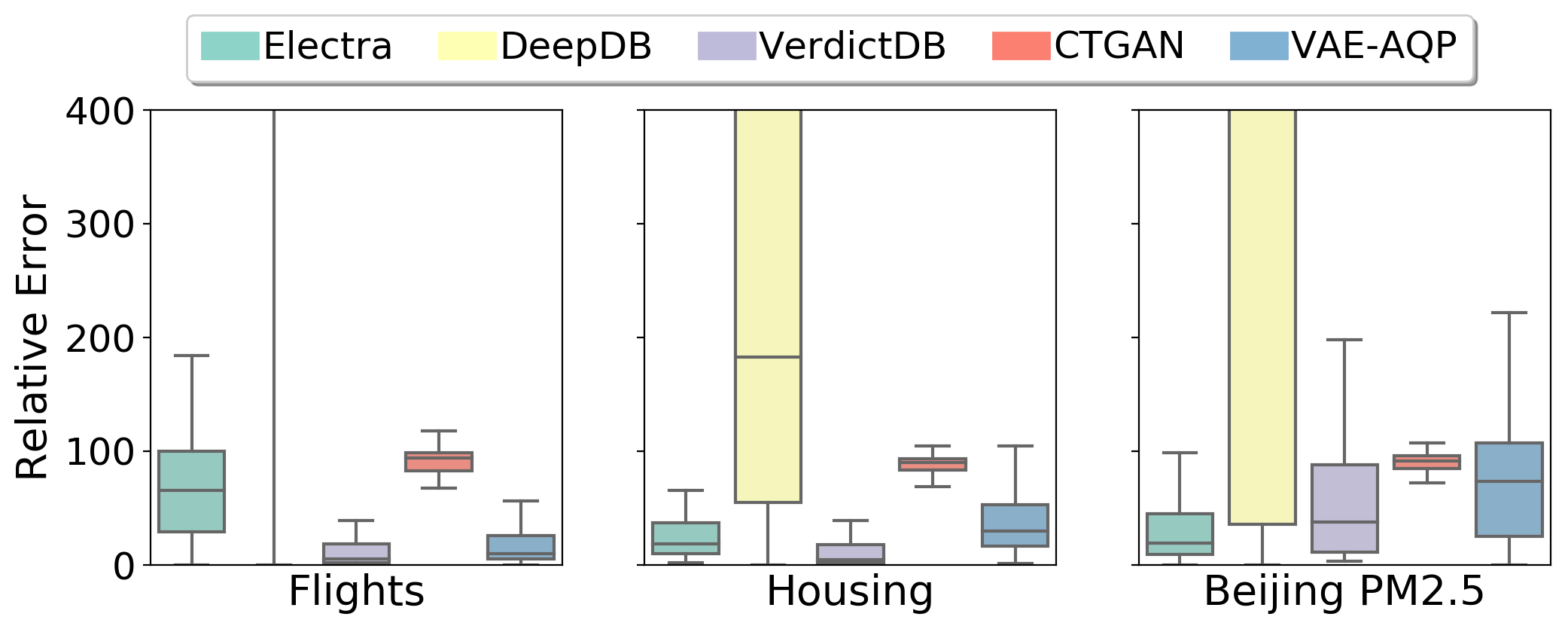 SUM Queries
SUM Queries
Contributors
- Nikhil Sheoran «sheoran2@illinois.edu»
- Subrata Mitra «subrata.mitra@adobe.com»
- Vibhor Porwal «viporwal@adobe.com»
- Anup Rao «anuprao@adobe.com»
- Tung Mai «tumai@adobe.com»
- Siddharth Ghetia
- Jatin Varshney
- Vikas Madukkuri
- Laxmikant Mishra